
|
最近遇到一个项目的后期扩容,使用到一个国外的实时/历史数据库产品:eDNA,由于eDNA是本人10多年前进入电力行业使用的第一个行业软件且工作了多年,因此这次乍一见,就勾起了10年前的一些回忆,由于自己从事实时/历史数据库这类产品的工作累计有9年的历史,因此也就趁热打铁,在此聊聊这个比较另类的实时/历史数据库产品:eDNA,另外也聊聊我对实时/历史数据库这类小众产品的看法。 在工控行业,提起实时数据库,多数人对此名词应该都不会陌生,因为在工控行业的软件从业人员在工作中基本都会遇到实时数据库或者集成了实时数据库的软件产品,常见的各种组态软件也好,SCADA系统也好,dcs系统中的上位软件的后台都有一个实时数据库,因此、实时数据库并不是一个高大上的东西。而作为历史数据库,也是个顺理成章的事情,数据要被存储起来用于分析计算,那么必然就需要一个历史数据库了。在组态软件、SCADA系统中,由于业务的重点价值是工艺流程的监视、控制及统计分析,强调的是应用,因此软件后台使用实时数据库和历史数据库就不是重点了。 而实时/历史数据库被炒作为高大上的东西的发迹时期大概是2000年前后,当时国内各行各业的自动化发展可谓是如火如荼,电力、石化等行业的生产过程自动化化大大提高后,建设数字化工厂、两化融合等概念就被提出并越炒越热(当然这些概念也并非完全炒作,是有实际意义的,这个时候国外已经发展得比较好了),于是在当时国内自动化和信息化发展比较好的几个行业,如发电、电力、石化等就开始了实际的系统建设,由于建设的系统是一个打通工厂生产流程和企业经营管理的一个系统,在各行业都给这个系统取了名字,有叫它MES的,有叫它SIS的,也有叫它生产调度的,还有……,总结一下呢,这个系统的基本功能主要如下: 1) 收集整个企业所有的生产设备的过程数据并长期保存这些过程数据。 2) 在企业办公网络中再现企业所有的生产流程,并以工艺流程图的方式展示。 3) 对整个企业的生产过程中的事件及报警等信息进行过滤、筛选、分析、统计等,以各种方式展示给用户 4) 对整个企业的生产过程的数据进行长期保存,并定期进行数据的统计分析,生成各种相关的生产报表。 5) 将企业实际的生产过程数据利用各类算法或经验分析方法处理后,得到分析结果,作为企业生产管理的决策依据。 由于此系统收集并存储的生产过程数据是整个企业的,因此数据量比各个生产车间使用的监控系统要大很多,一般来说、这种全厂级别的生产管理系统中的标签点数(此处的标签点属于工控行业在的惯用叫法)大概是几万到上百万,生产车间的监控系统的标签点数一般是几十到几千。因此在当时的现实情况下,现有的一些监控组态软件很难胜任此工作;而当时的关系数据库在处理工业生产设备的这类实时数据和海量历史数据的时候,又显得有些力不从心。于是,实时/历史数据库就获得了很好的市场机会。于是在2000年后五、六年中,实时/历史数据库如雨后春笋般的纷纷出现,又在这几年经过优胜劣汰,剩下几家。 前几段介绍了一下实时/历史数据库的背景,现在言归正传,聊聊本文的主角eDNA。 实际上本文的主角eDNA只是个无名小卒而也,据说eDNA最早出生于美国太平洋煤气电力公司,上世纪90年底由美国太平洋煤气电力公司的两名工程师开发并在企业内使用后,发现效果不错,因此这两位工程师就从美国太平洋煤气电力公司辞职出来双飞了。经过了7,8年后,时逢中国电力大发展,被一商人引入中国大陆,加上地利、人脉,取得了不错的发展,真应了雷军的那句话:“站在风口,猪都能飞起来。”而当时也是由于市场的需求旺而国产的实时/历史数据库产品未成熟,因此让国外的实时/历史数据库产品,如OSISoft公司的PI,Aspen公司的IP21等赚足了钱,所幸的是今天的国产实时/历史数据库产品经过10来年的发展,已经在整体性能及稳定性方面不弱于国外的实时/历史数据库产品了,而且在产品的易用性方面更是超过国外的产品,当然在品牌知名度及扩展功能的丰富性方面还需继续努力。
|
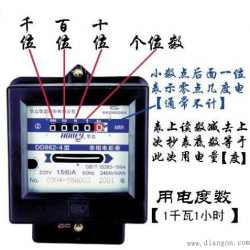 电表怎么看度数
电表怎么看度数 插座烧毁原因_插座烧后还可以继续使用吗?
插座烧毁原因_插座烧后还可以继续使用吗? 注册电气工程师考试挂靠,到底富了谁?
注册电气工程师考试挂靠,到底富了谁? 电工证可以“挂靠“吗
电工证可以“挂靠“吗 电工证怎么考?如何自考电工证
电工证怎么考?如何自考电工证 电工证种类和图片大全
电工证种类和图片大全电工学习网 ( )
GMT+8, 2021-12-6 20:47
